Dieser Blogpost versucht, die aktuelle Kritik am E-Voting-System der Schweizerischen Post laienfreundlich zu erklären. Der Fokus liegt dabei auf der mangelhaften Code-Qualität des Projektes.
Auf viele weitere wichtige Punkte (Fundamentalkritik am E-Voting, Vertrauensdiskussion, usw) wird hier nicht näher eingegangen.
Etwas noch vorneweg: Das E-Voting-Moratorium möchte auf dem Initiativweg einen mindestens 5jährigen Stopp für E-Voting-Projekte erwirken, bis die Sicherheitsproblematik gelöst ist. Für die Unterschriftensammlung werden noch viele Helfer gesucht! Auf Wecollect kann man sich dafür eintragen.
Einleitung
Seit dem Jahr 2000 finden in der Schweiz E-Voting-Versuche statt. Diese Versuche liefen zu Beginn immer in einem sehr begrenzen Rahmen ab. Eine Vorreiterrolle hatte dabei der Kanton Neuenburg. Er setzte dazu eine Software des spanischen Herstellers Scytl ein. Falls dieser Name bekannt erscheint, ist das kein Zufall: Scytl ist ebenfalls der Zulieferer des aktuellen (und des letzten in der Schweiz übrigbleibenden) E-Voting-Systems der Schweizerischen Post. Ich werde an dieser Stelle nicht näher auf Scytl und ihre zweifelhafte Rolle in dieser ganzen Sache eingehen, denn das hat das Magazin "Republik" bereits sehr gut abgedeckt.
Im Jahr 2009 wurde die Berner Fachhochschule auf das Projekt aufmerksam und kritisierte es stark. Ihr Vorwurf: Bei der elektronischen Stimmabgabe kann manipuliert werden. Die Vorwürfe führten dazu, dass das Projekt vorläuftig gestoppt wurde und neue Anforderungen definiert wurden: Ein E-Voting-System muss sicher und überprüfbar sein. Die BFH engagierte sich hier auch stark, um eine Spezifikation für ein solches zumindest in der Theorie sicheres System zu entwickeln. Die resultierende Spezifikation wurde veröffentlicht und ist frei zugänglich. Vorbildlich!
Es wurden also neue, auf äusserst komplexen und relativ neuen kryptografischen Algorithmen aufbauende Systeme entwickelt. Einerseits das System des Kantons Genf, welches ab Ende 2019 aus Kostengründen aufgrund der hohen Sicherheitsanforderungen nicht mehr weiterentwickelt wird. Anderseits das von Scytl entwickelte System, welches die Schweizerische Post verkauft.
Die Spezifikation und fundierte kryptografische Algorithmen sind aber nur ein Teil des Ganzen. Die Mathematik muss auch in die Praxis – in Programmcode – umgesetzt werden. Die Erfahrung zeigt: Dies ist äussert schwierig und fehleranfällig. Praktisch jede Software hat Fehler. Bei kritischer Infrastruktur wie E-Voting-Systemen ist es absolut essentiell, dass Systeme von erfahrenen Sicherheits-Spezialisten entwickelt werden. Die Qualität und Sicherheit hat absolut oberste Priorität.
Es gibt Prozesse, die dabei helfen, höchstmögliche Qualität zu erzielen. Beispiele dafür sind Code Review, Statische Code-Analyse, Dynamische Code-Analyse, Continuous Integration und vieles mehr. Ebenfalls essentiell: Code muss so geschrieben werden, dass falsche Anwendung des Codes möglichst unmöglich wird. Das kann man unter anderem durch Programmiersprachen mit einem starken Typsystem erreichen, wie Ada, OCaml oder Rust. (Java, welches von Scytl verwendet wird, gehört nicht zu dieser Art von Programmiersprachen.)
In der Software-Industrie und der dazugehörigen Disziplin des Software-Engineering gibt es klare Best Practices, die in kritischen Situationen eingesetzt werden. Diese werden in gewissen Branchen wie der Aviatik- oder Automobilbranche auch forciert.
Offenlegungspflicht
Um das Vertrauen der Öffentlichkeit in das System zu stärken, gibt es eine spezielle Anforderung an ein Schweizer E-Voting-System: Der Quellcode muss offengelegt werden. Zitat aus der Verordnung über die elektronische Stimmabgabe (VEleS) Art. 7:
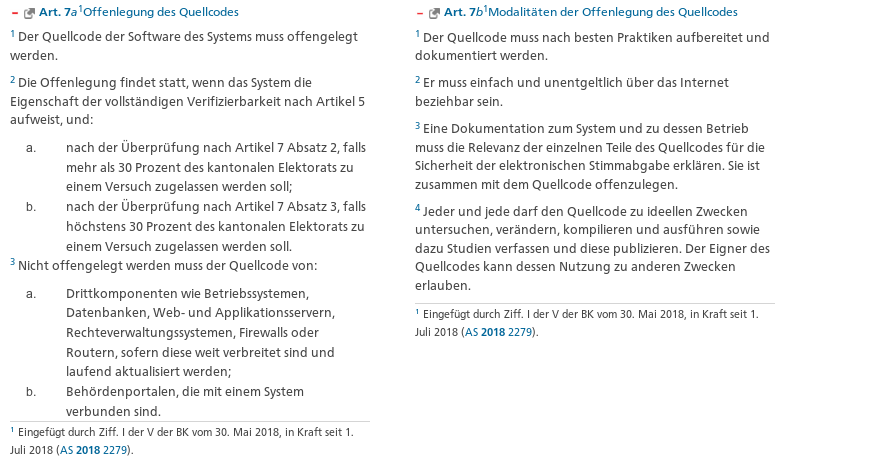
Der offengelegte Code muss nach "besten Praktiken" aufbereitet und dokumentiert werden. Eine Dokumentation zum System und dessen Betrieb muss beiliegen. "Jeder und jede" darf den Quellcode "zu ideellen Zwecken untersuchen, verändern, kompilieren und ausführen sowie dazu Studien verfassen und diese publizieren".
Die Post hat den Quellcode ihres E-Voting-Systems vor wenigen Tagen veröffentlicht. Naja, zumindest teilweise. Um auf den Quellcode zugreifen zu können, müssen zuerst ihre Bedingungen akzeptiert werden. Darin stehen ein paar problematische Dinge, auf die ich an dieser Stelle nicht eingehen werde.
Die Verordnung verlangt, dass "jeder und jede" den Quellcode untersuchen darf. Die Leute, die die Bedingungen akzeptiert haben, sind jedoch eine Untermenge von "jeder und jede". Ob dies legal ist? Ich weiss es nicht. Die Post stützt sich jedenfalls auf ihre Immaterialgüterrechte und betrachtet den Quellcode als veröffentlicht.
"Es gibt keine Restriktionen, sofern man unsere Restriktionen akzeptiert". Habe ich das richtig verstanden? #evoting
— Danilo (@dbrgn) February 19, 2019
Unzufrieden mit den Bedingungen, veröffentlichte eine unbekannte Person den Quellcode auf gitlab.com. Dies ermöglichte allen interessierten Personen, sich den Code ohne Einschränkungen näher anzusehen.
Codequalität: Komplexität
Sarah Jamie Lewis ist Gründerin von Open Privacy und Sicherheitsforscherin mit viel Erfahrung im Auditieren von sicherheitsrelevanten Enterprise-Systemen. Zu ihren früheren Arbeitgebern gehören Amazon und der britische Geheimdienst GCHQ. Sie weiss, worauf es ankommt, wenn man sicheren Code schreiben will.
Auf den ersten Blick war sie nicht gerade begeistert vom E-Voting der Post:
So, I took a look at swiss online voting system code that someone leaked, and having written, deployed and audited large enterprise java code...that thing triggers every flag.
— Sarah Jamie Lewis (@SarahJamieLewis) February 17, 2019
Erste Kritik: Der Quellcode für das sogenannte Mixnet (welches die Zuordnung von Stimmen zu Personen trennt) ist über viele verschiedene Dateien verteilt, so dass es sowohl für Entwickler wie auch Prüfer sehr schwierig ist, den Überblick zu bewahren. Das ist sehr schlecht wenn es um Kryptografie geht, da man kryptografischen Code so einfach und übersichtlich wie möglich halten will, weil ansonsten die Wahrscheinlichkeit von Fehlern steigt.
The core reencryption mixnet code is spread across dozens of different files, not included the auxiliary/utility/deployment packages.
— Sarah Jamie Lewis (@SarahJamieLewis) February 17, 2019
Also this work in progress is reassuring pic.twitter.com/v93km0T41E
Das gibt schon einen Hinweis auf einen ganz wichtigen Aspekt bei solchen Systemen: Sie sollten so einfach verständlich sein wie möglich! Auch Programmierer sind nur Menschen und machen Fehler. Die Fehlerwahrscheinlichkeit ist ungleich höher, wenn der Code Komplex ist.
Und komplex, das ist der Code in diesem Fall:
I've just spent an hour of my precious life trying to determine the encryption parameters used in the above proofs and I still have no clue, every example config/parameter that relates to it seems to be no where close to sensible or secure - which is a big flag by itself.
— Sarah Jamie Lewis (@SarahJamieLewis) February 17, 2019
Gleichzeitig wurde auch Matthew Green auf den Code aufmerksam. Matthew ist Professor für Kryptografie an der renommierten John Hopkins Universität. Er forscht primär im Feld der Angewandten Kryptografie. Dabei geht es explizit darum, wie kryptografische Systeme (wie z.B. E-Voting) sicher in der Praxis umgesetzt werden können. Matthew hat einen sehr guten Ruf, hat schon dutzende wissenschaftliche Publikationen veröffentlicht und ist mit 87'000 Followern auch auf Twitter ziemlich bekannt.
Das ist seine Meinung zum Code der Post:
As some kind of penance I spent the day poking through their specs and code and OH LORD I love complicated crypto, but this terrifies even me. I can’t even make sense of some of these code patterns to find the right routines, let alone verify they’re correct. 6/
— Matthew Green (@matthew_d_green) February 18, 2019
Sein Fazit:
So to summarize this long tweet thread: *no* it is not the case (apparently) that this code is trivially broken. *no*, that does not make it safe to use in real elections, nor (as far as I know) has it been audited by anyone competent enough to really bless it. 16/
— Matthew Green (@matthew_d_green) February 18, 2019
Sowohl Matthew wie auch Sarah kritisieren in diesen Tweets nicht konkrete Fehler oder Sicherheitslücken. Was sie sagen ist, dass der Code nicht nach Best Practices geschrieben ist. Er ist komplex, er ist über viele verschiedene Dateien verteilt, er ist fehleranfällig. Und so komplexer Code kann kaum vollständig auditiert werden.
That last point applies most to my critique thread - it is impossible to audit security sensitive code split across 20 different packages, references 30 different classes and interfaces, and configured at runtime via JSON.
— Sarah Jamie Lewis (@SarahJamieLewis) February 18, 2019
In der Praxis passieren die meisten Fehler nämlich nicht in den Kernalgorithmen, sondern im Zusammenspiel der verschiedenen Komponenten:
More so, the majority of application-level security bugs happen at the intersection of code packages e.g. calling the wrong method, referencing the wrong config file etc.
— Sarah Jamie Lewis (@SarahJamieLewis) February 18, 2019
Even if the isolated code is perfect, the potential for integration misuse is high.
Und die Konsequenzen eines Fehlers wären fatal für das Vertrauen in die Schweizer Demokratie:
Change votes, collide Pedersen commitments, completely own the election.
— Matthew Green (@matthew_d_green) February 17, 2019
And if they don’t use properly-generated groups produced verifiable from a seed (as in FIPS 186) then there are other attacks a malicious election admin can pull off.
Codequalität: Defensiver Programmierstil
Beim Schreiben von sicherem Code geht es aber nicht nur um die Komplexität. Es geht auch um das Fehlerverhalten. Falls sich doch irgendwo ein Fehler enschleicht, soll dieser möglichst die negativen Auswirkungen minimieren.
Mistakes happen. All the time. Even the best engineering teams on the planet sometimes screw up.
— Sarah Jamie Lewis (@SarahJamieLewis) February 18, 2019
The goal of security driven design is to minimize the impact of mistakes.
Ein Beispiel: Wenn ein kryptografischer Beweis einer Stimme verifiziert werden soll, dann ist es schlimmer wenn eine ungültige oder gefälschte Stimme als gültig erklärt wird, als wenn eine gültige Stimme als ungültig erklärt wird und dann zu einer Fehlermeldung führt.
Man sollte also von der Grundannahme ausgehen, dass der Beweis ungültig ist, um anschliessend das Gegenteil zu beweisen. Scytl hat offenbar von diesem Prinzip noch nichts gehört: Die Funktion, die prüft ob ein Beweis gültig ist, geht von der Grundannahme aus, dass alles in Ordnung ist. Dies erhöht die Fehlerwahrscheinlichkeit. Sarah war nicht begeistert.
oh ffs, how about some basic defense in depth people. This is not how you start a function designed to verify a proof as being correct.
— Sarah Jamie Lewis (@SarahJamieLewis) February 17, 2019
*headdesk* pic.twitter.com/NRtIWGdwZR
Codequalität: Automatisierte Tests
Korrekten Code zu schreiben ist herausfordernd. Noch viel herausfordernder ist es, Code zu schreiben welcher sich auch bei Veränderung oder Erweiterung des Systems immer noch korrekt verhält. In der Software-Industrie weiss man dies schon lange, deshalb verwendet man automatisierte Tests um die Grundannahmen und korrekte Funktionsweise des Systems schnell und regelmässig zu überprüfen. Typischerweise werden diese Tests automatisiert bei jeder Änderung des Programmcodes ausgeführt. Eine Änderung wird nur in das Projekt integriert, wenn diese Tests erfolgreich sind. Besonders wichtig ist dies natürlich bei allem, was Kryptografie betrifft.
Die Tests im Quellcode der Post sind lückenhaft.
If anyone can point me towards the tests for the proof code that would be good because....I can't find any.
— Sarah Jamie Lewis (@SarahJamieLewis) February 17, 2019
Und so wie es aussieht, sind sich manchmal nichtmal die Entwickler selbst ganz sicher, ob die Tests wirklich das testen was sie testen sollten 😉 (Zeilen 72 und 73 im folgenden Screenshot.)
Woah, that's a true gem 😂 https://t.co/N2TlFLNCPd #evoting #switzerland #audit #securitytheater pic.twitter.com/zU8TFSwx22
— Danilo (@dbrgn) February 20, 2019
Codequalität: Prozesse
Jede Software-Ingenieurin und jeder Kryptografie-Experte macht mal Fehler. Das ist menschlich. Eines der effektivsten Mittel, um die Fehlerrate um 30-60% zu verringern, ist das Code Review (also das gegenseitige Gegenlesen und Prüfen von neuem Programmcode). Konsequent umgesetzte Code-Review-Prozesse verlangen, dass kein Code ins System gelangen darf, welcher nicht von einer weiteren Person mit Fachkenntnissen angeschaut und für gut befunden wurde. Code Review ist für hohe Qualität in einem sicherheitsrelevantem Umfeld unabdingbar.
Den folgenden Tweet für Laien zu erklären ist etwas schwierig, deshalb zusammengefasst: Wie es die untenstehenden Konfigurationsdateien mit nicht aufgelösten Merge-Konflikten durch einen Code-Review-Prozess geschafft haben, ist mir unerklärlich. Ausser natürlich, wenn es bei Scytl kein konsequentes Code Review gibt. Hmmmmm... 🤔
Funniest finding in the @postschweiz #evoting sourcecode so far: There are about a dozen files with unresolved or partially resolved git merge conflicts 😆
— Danilo (@dbrgn) February 20, 2019
How do such simple things pass code review?
(Yes, it's not security relevant. But it indicates sloppy processes.) pic.twitter.com/upjEf5YVav
Codequalität: Analyse-Tools
Selbst bei Code-Reviews werden gewisse Probleme ab und zu übersehen. Um Software weiteren Checks zu unterziehen, gibt es daher statische Code-Analyse-Tools, welche den Quellcode untersuchen und potentielle Probleme und Fehler aufzeigen.
Ein vereinfachtes Beispiel: Ein Reisebüro programmiert ein Anmelde-Formular für eine Ferienreise. In diesem Formular ist der Name ein Pflichtfeld und der Kunde muss mindestens 18 Jahre alt sein. Das Reisebüro schreibt also zwei "Code-Schnipsel" (Funktionen), das erste prüft ob ein Textfeld nicht leer ist und das zweite prüft ob eine Jahrgangs-Zahl tiefer ist als 2001.
Nun könnte ein Flüchtigkeitsfehler passieren, so dass sowohl beim Namen wie auch bei der Jahreszahl nur geprüft wird, ob das Feld nicht leer ist. Der Code, welcher prüft ob eine Zahl kleiner als 2001 ist, ist somit ungenutzt (sogennanter "Dead Code"). Das Formular scheint auf den ersten Blick zu funktionieren, allerdings ist die Validierung subtil falsch (allerdings nur bei gewissen Eingabewerten, nämlich wenn sich eine minderjährige Person registriert). Solche Fehler sind eher schwierig zu entdecken, da auf den ersten Blick alles korrekt zu funktionieren scheint. Statische Code-Analyse kann solche Fehler aufdecken und warnt, wenn Code im Projekt enthalten ist, welcher gar nie benutzt wird.
Ungenutzter Code ist nur eines der vielen Probleme, die mit statischer Code-Analyse aufgedeckt werden kann. Wie der folgende Screenshot von Sarah zeigt, hat ein Code-Analyse-Tool beim Prüfen des E-Voting-Programmcodes 436 Warnungen generiert. Ob darunter echte Fehler stecken, weiss ich nicht. Viele Projekte haben aber Richtlinien, die besagen dass alle Warnungen entweder behandelt oder explizit deaktiviert werden müssen ("No-Warnings Policy").
Some of the proof code involves copying commitments into structures that are never accessed.
— Sarah Jamie Lewis (@SarahJamieLewis) February 21, 2019
Are they supposed to be accessed? Is this dead code? Who the fuck knows.
Ein weiteres verbreitetes Code-Analyse-Tool prüft Code auf Abhängigkeiten zu Drittkomponenten, welche veraltet sind und Sicherheitslücken enthalten. Auch hier gab's auf Anhieb mehrere Treffer.
Seriously this code doesn't even begin to approximate the standard that should be expected of a system designed to secure the integrity of public elections.https://t.co/jjStoJ22Qw
— Sarah Jamie Lewis (@SarahJamieLewis) February 20, 2019
Ob diese Fehler in Drittkomponenten relevant sind, weiss ich nicht. Aber es ist zumindest beunruhigend, so viele potentielle Sicherheitslücken zu sehen.
Fazit
Ich hoffe, ich konnte einen kleinen Einblick in moderne Software-Entwicklungsmethoden geben. Von einer Firma wie Scytl, deren Slogan "We Power Democracy" lautet, sollte man Entwicklungsprozesse auf höchstem Sicherheitsniveau erwarten können. Solche Erwartungen wurden in den letzten Tagen aber hart auf den Boden der doch eher beängstigenden Realität zurückgeholt.
Selbst wenn beim Intrusion-Test der Post keine Sicherheitslücken gefunden werden sollten (was ich für beinahe ausgeschlossen halte), bleiben die Eindrücke der unzulänglichen Entwicklungsprozesse bestehen. Auch wenn das System den Intrusion-Test erfolgreich "bestanden" hat, ist dies kein Sicherheitsbeweis. Einen solchen wird es nie geben.
"Also you only get the bounty if the bridge collapses, reports of systemic structural unsoundness will not qualify"
— Sarah Jamie Lewis (@SarahJamieLewis) February 17, 2019
Neben der Sicherheit wurden ganz viele kritische Aspekte von E-Voting (Vertrauen, Nachvollziehbarkeit, Finanzen, Abhängigkeiten, Wahrung des Stimmgeheimnisses und vieles mehr) von diesem Post noch gar nicht abgedeckt... Was braucht es denn, um in der Schweiz eine sichere und vertrauenswürdige Demokratie zu erhalten? Gemäss Sarah könnten wir's mal mit Glück probieren:
Anyway, I wish the swiss election team the best of luck in ensuring that the thousands of new, highly configurable, ZKP code, written in Java, decomposed over hundreds of files, is up to the standard of securing national elections.
— Sarah Jamie Lewis (@SarahJamieLewis) February 18, 2019
Alternativ könnte man auch auf Wecollect das parteiübergreifende E-Voting-Moratorium unterstützen.
Als technischer Laie vermag ich #evoting nicht im Detail zu durchschauen, doch gesunder Menschenverstand sagt mir: Demokratie muss analog bleiben - genau wie Fortpflanzung und Nahrungsaufnahme ! https://t.co/SmI7UYAM7k
— Markus Felber (@Frechgeist) February 21, 2019
Danke für's Lesen!
Weiterführende Links:
- Motherboard: Experts Find Serious Problems With Switzerland's Online Voting System Before Public Penetration Test Even Begins
- Republik: Postschiff Enterprise
- Republik: Das heikle Geschäft mit der Demokratie
- noevoting.ch
Update 2019-02-25: Nach 3 weiteren Tagen der Code-Analyse hat Sarah folgendes Fazit gezogen: "lol burn it with fire" ("Haha, verbrennt es mit Feuer")
Since I see many articles written in many languages quoting me about the evote thing, I would like to update my opinion:
— Sarah Jamie Lewis (@SarahJamieLewis) February 24, 2019
My new opinion is, and this is important so please quote me accurately: lol burn it with fire.